BigQuery, Google’s data warehouse solution, supports nested and repeated fields that simplify data loading and query performance by denormalizing data. Denormalization adds data columns to a single table, reducing the need for table joins that can negatively impact performance, especially with larger datasets. This practice proves especially valuable when dealing with hierarchical relationships that are queried frequently.
Understanding Nested and Repeated Fields
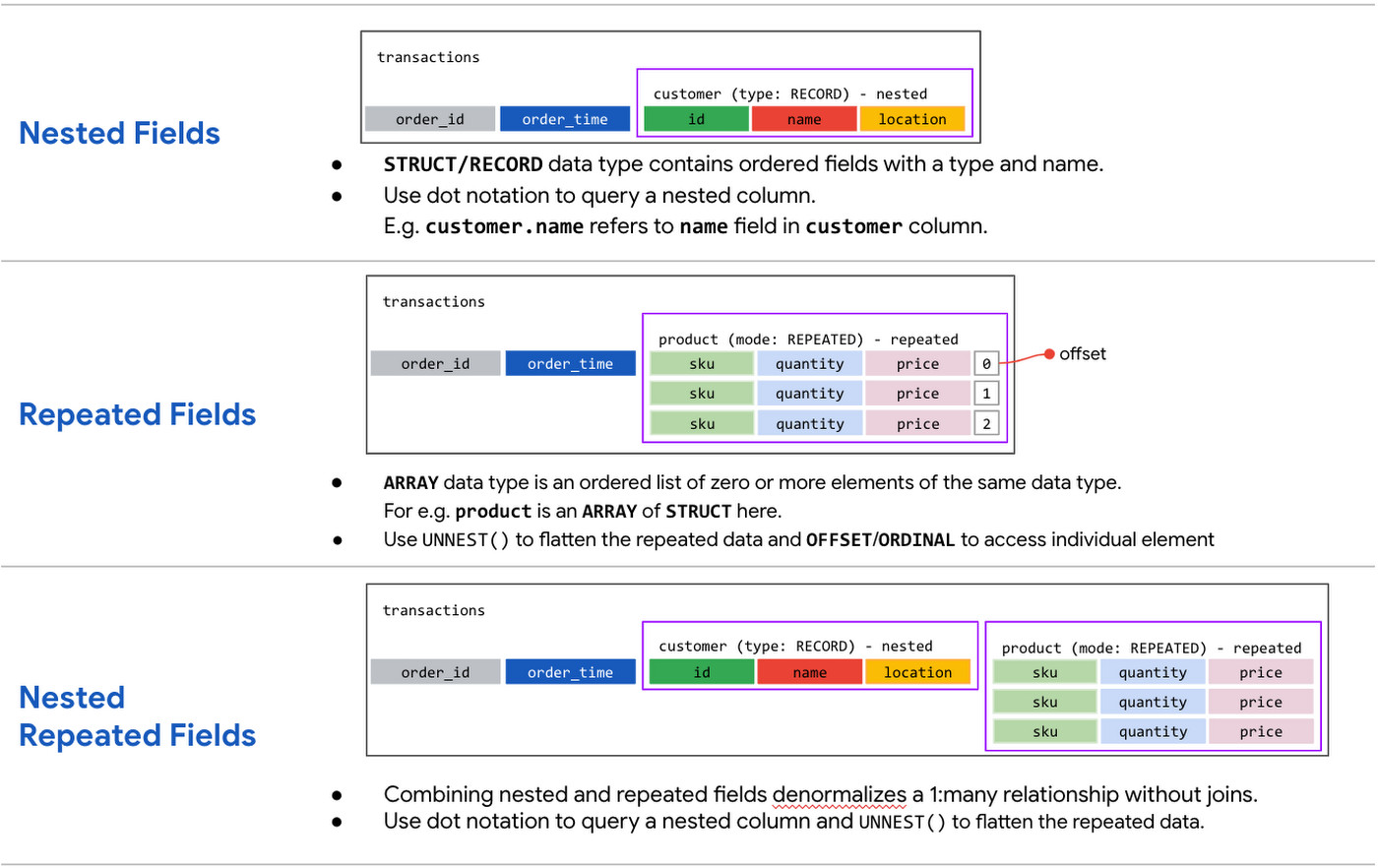
Nested fields function similarly to structs or objects, grouping related data together. They are defined as RECORD types in BigQuery’s schema and accessed using dot notation in SQL queries. For instance, an address field might contain nested fields like city, state, and zip.
Repeated fields allow storing multiple values within a single row, akin to a one-to-many relationship. These fields are defined as ARRAY types and can be queried effectively using the UNNEST() function. For example, a product field in an orders table could hold an array of products purchased in that order.
Nested and repeated fields can be combined to represent complex relationships within a single table, eliminating the need for joins. This approach proves particularly effective for e-commerce data where an orders table can have a nested, repeated field for products, each containing details like name, quantity, and price.
Advantages of Nested & Repeated Fields
- Improved Query Performance: Storing related information in a single row avoids costly joins, leading to faster query execution.
- Simplified Data Loading: Nested and repeated fields allow loading data from JSON or Avro files directly into BigQuery tables without complex transformations.
- Data Modeling Flexibility: These fields provide a more natural representation of hierarchical data relationships.
Querying Nested and Repeated Fields
Nested fields are easily queried using dot notation, specifying the path to the nested field within the query.
Repeated fields require the UNNEST() function to expand the array elements into separate rows, enabling more straightforward querying.
Joining tables based on repeated fields often involves using CROSS JOIN UNNEST() to generate all possible combinations of values from the unnested array and the original table.
Guidelines for Using Nested and Repeated Fields
- Consider denormalizing dimension tables larger than 10 GB to leverage the performance benefits of nested and repeated fields.
- For dimension tables smaller than 10 GB, normalization may be more suitable unless update and delete operations are infrequent.
- Be mindful of potential pitfalls when querying repeated fields:
- Use LEFT JOIN UNNEST() to avoid omitting records with null values in the repeated field.
- Employ COUNT(DISTINCT …) when counting records to avoid overcounting due to multiple nested values.
Conclusion
Nested and repeated fields in BigQuery offer a powerful mechanism for denormalizing data, boosting query performance, and simplifying data loading for complex, hierarchical datasets. By understanding their nuances and employing best practices for querying, you can leverage these features to build efficient and scalable data warehouses within BigQuery.
Sources: